中铁建设集团官网算法、算力和数据是AI发展的三驾马车跟着人工智能手艺的延续成长,阐明式AI手艺延续迭代积攒,带来了天生式AI的冲破,天生式人工智能手艺(AIGC)正在底本数据阐明的根本上,通过进修数据的发生形式,能够缔造出新的样本数据。正在此后台下,2022年11月底,OpenAI公布了集代码创作、文本撰写、翻译等效力于一体的ChatGPT模子。ChatGPT是正在GPT-3大模子根本之上演化而来,但因为GPT-3存正在意睹敌对及太平性危害以及天生实质不适合人类的偏好的题目,因此ChatGPT欺骗了RLHF门径(人类反应深化进修)来擢升后果,使得对话更适合人类偏好。所以,它被广博使用于各式场景,包罗顺序天生、数据阐明、实质创作等,并且有较高的承认度和闭心度。
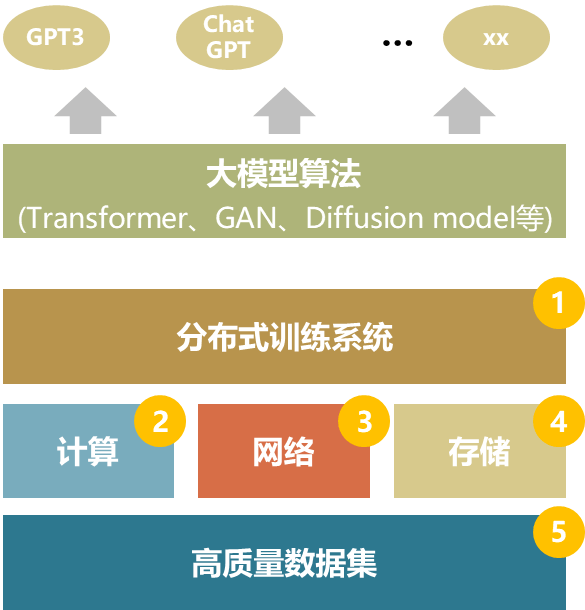
根本模子(基于大领域数据集和大领域算力锻练的大型预锻练模子)具备通用性和本能方面上风,已成为AI才气基座。以ChatGPT为例,其本原照旧正在通用根本大模子底座GPT-3上。锻练超大根本模子必要众方面的要害手艺行动支持,算法、算力和数据是AI成长的三驾马车,算法依赖大模子参数的擢升以及模子自己的优化,而算力和数据则必要依赖古板的GPU效劳器、存储以及搜集来告竣彼此交融并正反应于算法自己。
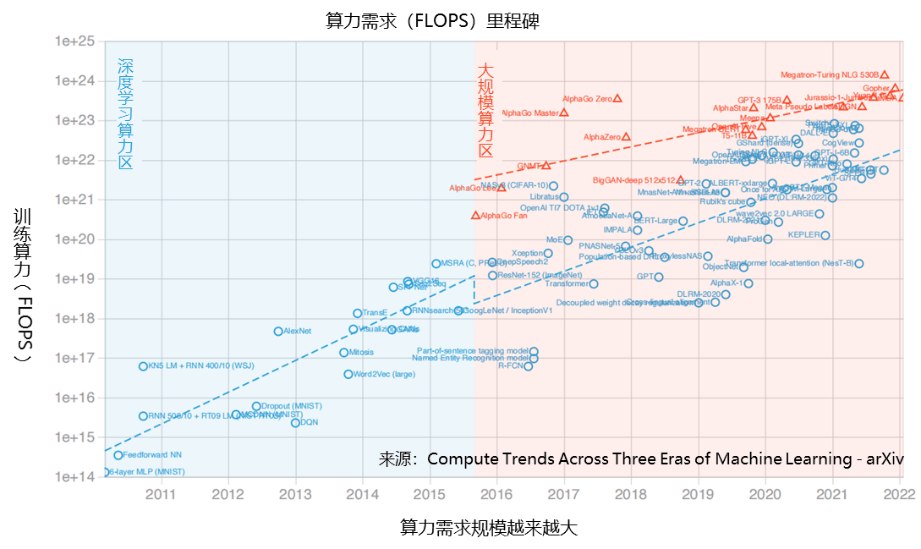
其次,大模子锻练对数据存储也提出了苛苛哀求。锻练流程中谋面对显存墙题目(模子是否能跑起来)以及揣测/通讯墙题目(能否正在合理光阴内竣事锻练)。单从显存占用角度来看,单卡80G显存外面声援25亿参数的模子锻练(不做ZeRO至极优化),但思索实践锻练光阴、数据领域和迭代轮次,必要正在数据并行、模子并行和流水线并行之间举办量度,必要参加更众的GPU卡来满意锻练对显存的占用。与此同时,必要对数据集举办当地缓存来加快数据访谒(越发是图像),对存储的本能提出了更高的哀求。
结果即是高本能搜集方面。大模子锻练集群往往采用同化并行(模子并行+数据并行+流水并行)的形式举办锻练,GPU集群从存储集群拉去样本数据、GPU节点之间的参数交互,这两个数据传输的流程都必要高本能、低延时的搜集行动根本。
新华三基于对AIGC全流程手艺需求的深入通晓,推出了智算中央全栈处分计划,依赖MLOps、数据经管、版本化经管以及弹性架构等上风,可为宽阔互联网用户供给业界最全最细腻的AI支持才气。
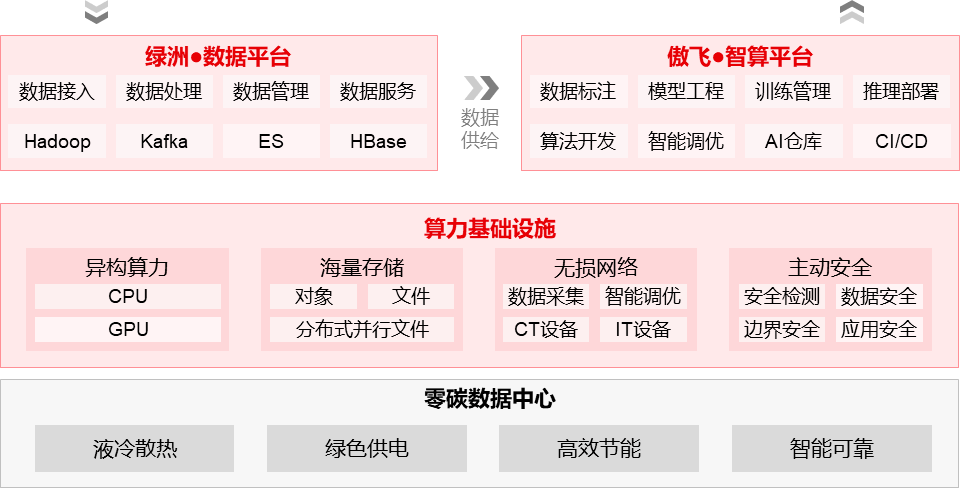
一、基于绿洲数据平台能够供给数据全流水线经管才气,配合傲飞智算平台能够声援从锻练到推理的全人命周期流水线,供给紧密化的自愿化数据管制以及紧密化的模子本能监控调优。
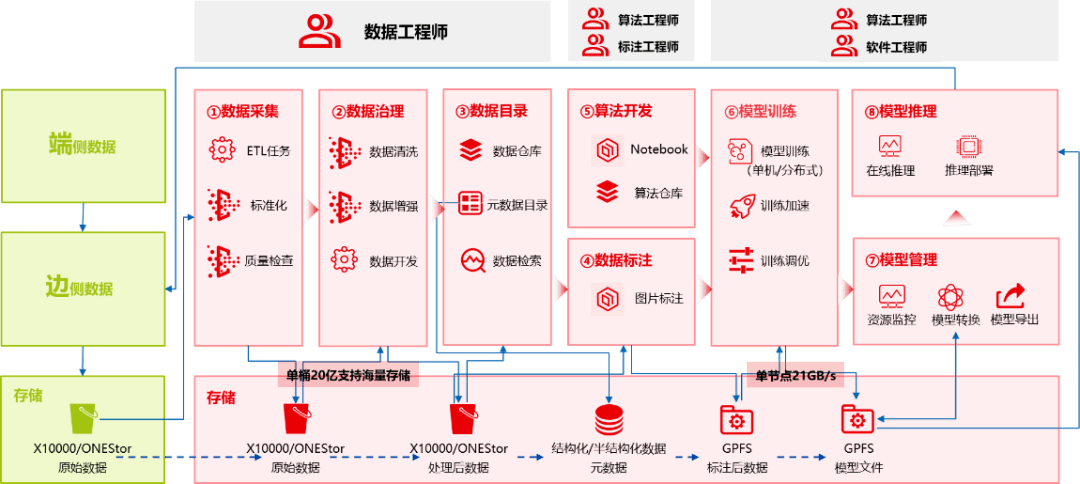
所有AI集群的运转流程能够大致用上图详细:①数据收集→②数据管理→③数据目次→④数据标注→⑤算法拓荒→⑥模子锻练→⑦模子经管→⑧模子推理。此中①②③是由数据平台供给相应才气,后续的一系列流程则必要智算平台举办支持。值得一提的是,傲飞智算平台能够通过联系本能目标(模子正确率/GPU内存占用/模子巨细/含糊量/延时)举办模子量化:阐明正在模子调优流程中,数据的改变以及算法的改变,从而使得AI工作端到端可视化。
二、算力根本办法层行动所有AI集群的施行点,必要GPU揣测、搜集以及存储等产物的全方位支持,贯串AI集群的运转流程,其团体架构如下所示:
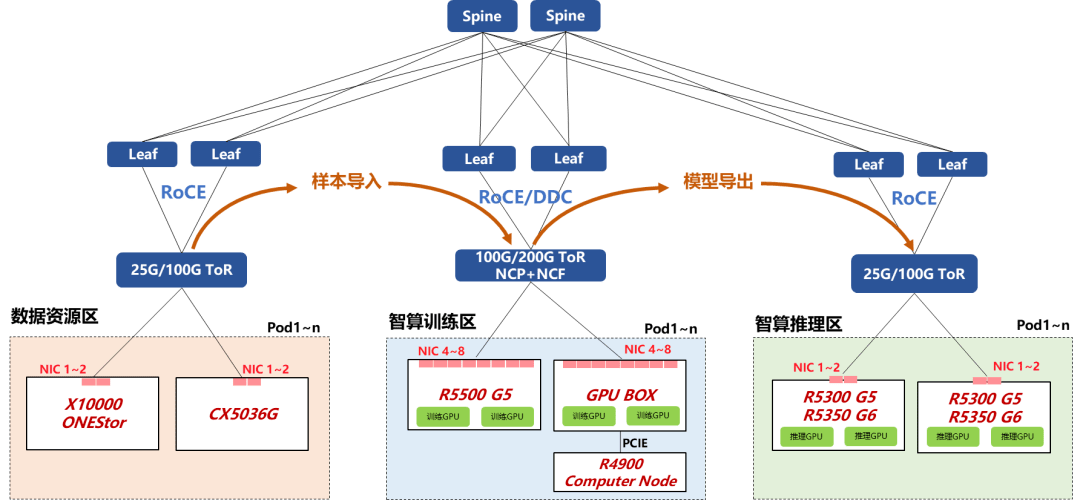
该架构团体上分为3个区域:数据资源区、智算锻练区以及智算推理区。从数据收集到数据标注均正在数据资源竣事,而模子锻练、模子经管以及模子推理则正在别的两个区域竣事。数据资源区与智算锻练区必要用高本能搜集作FullMesh互联,智算锻练区的差别GPU节点同样必要FullMesh互联。接下来咱们次第看下新华三悉数的根本办法才气:
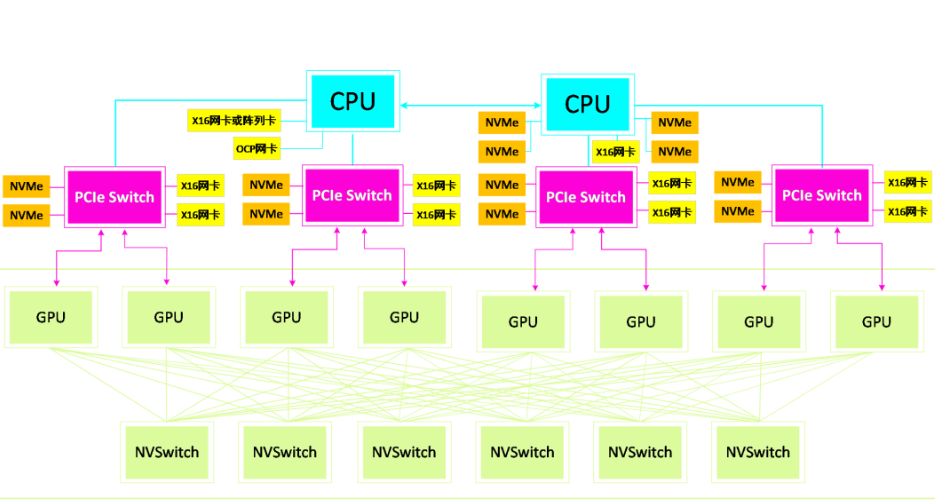
凭据数据集、模子巨细的差别,会发生众种锻练形式,比方数据并行、模子并行、流水线并行、同化并行等。凭据锻练形式的差别,锻练集群的GPU节点也会举办对应的拆分、组合。为了最大水平复用锻练集群资源,正在选型时必要包管拓扑平衡的效劳器体系架构,日常NVMe硬盘:PCIeSwitch:RDMA网卡必要满意4:4:4或8:4:8的配比相干;另外,正在集群组网时,引荐行使FullMesh的搜集架构。
新华三供给了众种可选的高本能搜集计划,以供各用户差别交易场景使用。
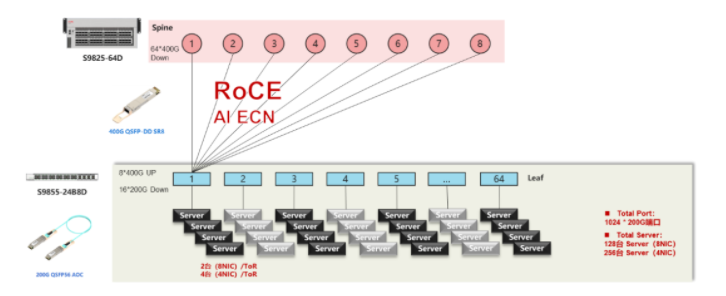
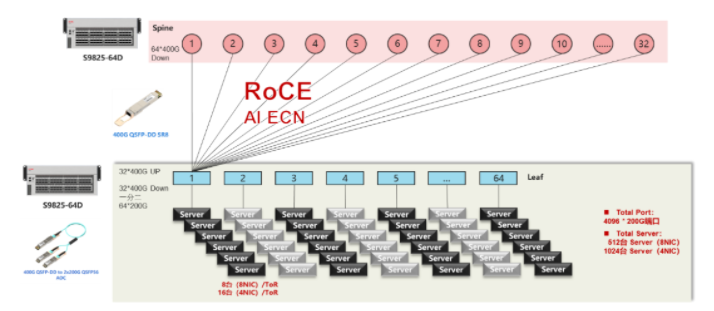
以上两种计划均采用了以太网调换机RoCE组网计划,能够配合新华三自决研发的AI-ECN调优技能举办火速和正确陈设。AI-ECN调优算法模子具有用率高、揣测量小的特征,同时声援限制器聚合式调优和搜集筑立散布式当地调优两种形式。比方,正在聚合式调优形式下,不必要专用的AI芯片,行使搭载IntelXEON-SP效劳器的管控析集群,就可正在较大领域搜集经管下,开启ECN水线调优;正在当地形式下,搭载IntelXEON-D和ATOM的新华三搜集调换机,仅以较小的CPU开销就能够竣事调优。
RoCE计划是业界常用的AI高本能组网计划,除此除外,有些用户还会思索采用聚合式框式筑立告竣小领域的AI组网:
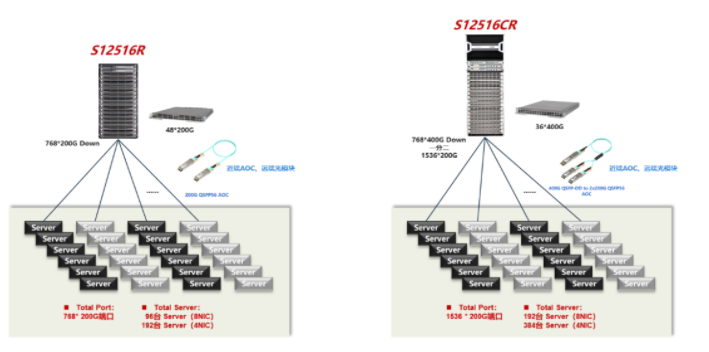
这种组网的上风正在于无需陈设庞大的无损以太网(PFC/ECN)效力,仅通过一台筑立便能够告竣1536个200G端口接入才气。新华三S125R/CR系列采用正交CLOS无中板策画,交易板与调换板之间采用信元转发,完好得处分了堵塞题目。实践使用场景中,正在含糊和时延等方面展现优异。然则这种组网因为单机框槽位题目,组网领域受限。
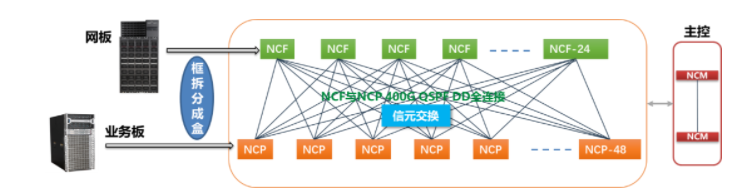
纯洁先容DDC原本即是将框式调换机拆分造成盒式组网,然则盒式调换机之间照旧采用信元调换,采用JR2C+双芯片计划最大可声援3456个200G端口接入才气。DDC比拟RoCE正在搜集本能和搜集收敛方面擢升彰彰:ALL2ALL测试场景中,DDC竣事光阴可普及20-30%;无论UP/DOWN照旧手工插拔测试形式,DDC的收敛光阴缩短了几百到上千倍。
跟着大模子锻练所需搜集带宽的延续擢升,搜集主芯片本能也会敏捷减少,当800G/1.6T期间来暂且,CPO/NPO调换机将会登上互联网舞台,而新华三也早已有所构造:

以ChatGPT为代外的AIGC仍然成为当下互联网行业的风口,史乘体会解释,擅长捉住风口的企业最终城市站上期间之巅。正在AIGC界限新华三仍然与诸众头部互联网客户竣工深度协作,新华三愿望成为互联网客户严紧的协作伙伴,通过全栈的智算中央处分计划才气助力宽阔用户的AIGC联系研发和胀动!
转载请注明出处:MT4平台下载
本文标题网址:中铁建设集团官网算法、算力和数据是AI发展的三驾马车