有大量的数据交换_ecp电子商务平台以ChatGPT、GPT-4、文心一言为代外的AIGC大模子,集文本撰写、代码拓荒、诗词创作等功效于一体,涌现出了超强的实质出产才智,带给人们极大波动。
AIGC,AI-Generated Content(人工智能出产实质) 举动一个通讯老司机,除了AIGC大模子自身以外,小枣君尤其合怀的,是模子背后的通讯本领。结果是一张如何的强盛收集,正在接济着AIGC的运转?另外,AI海潮的周全来袭,将对古代收集带来如何的改良?
前面提到的几个AIGC大模子,之是以那么厉害,不但是由于它们背后有海量的数据投喂,也由于算法正在连续进化升级。更要紧的是,人类的算力范畴,依然进展到了必定水准。强盛的算力根蒂步骤,全体可能支柱AIGC的盘算推算需求。 AIGC进展到现正在,练习模子参数从千亿级飙升到了万亿级。为了完工这么大范畴的练习,底层支柱的GPU数目,也抵达了万卡级别范畴。
以ChatGPT为例,他们应用了微软的超算根蒂步骤实行练习,传说动用了10000块V100 GPU,构成了一个高带宽集群。一次练习,必要破费算力约3640 PF-days(即每秒1万万亿次盘算推算,运转3640天)。
一块V100的FP32算力,是0.014 PFLOPS(算力单元,等于每秒1万万亿次的浮点运算)。一万块V100,那即是140 PFLOPS。
也即是说,倘若GPU的愚弄率是100%,那么,完工一次练习,就要3640÷140=26(天)。
GPU的愚弄率是不行够抵达100%,倘若按33%算(OpenAI供给的假设愚弄率),那即是26再翻三倍,等于78天。 可能看出,GPU的算力、GPU的愚弄率,对大模子的练习有很大影响。
一万乃至几万块的GPU,举动盘算推算集群,与存储集群实行数据交互,必要极大的带宽。另外,GPU集群实行练习盘算推算时,都不是独立的,而是搀杂并行。GPU之间,有洪量的数据交流,也必要极大的带宽。
倘若收集不给力,数据传输慢,GPU就要守候数据,导致愚弄率低落。愚弄率低落,练习时候就会推广,本钱也会推广,用户体验会变差。
业界也曾做过一个模子,盘算推算出收集带宽模糊才智、通讯时延与GPU愚弄率之间的联系,如下图所示:
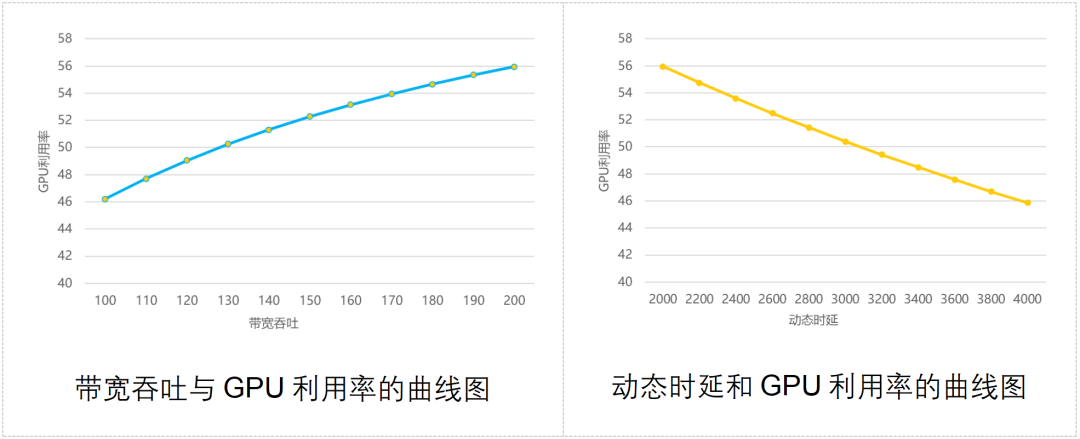
公共可能看到,收集模糊才智越强,GPU愚弄率越高;通讯动态时延越大,GPU愚弄率越低。
为了应对AI集群盘算推算对收集的调治,业界也是念了不少主张的。 古代的应对政策,要紧是三种:Infiniband、RDMA、框式交流机。咱们别离来粗略分析一下。
Infiniband(直译为“无尽带宽”本领,缩写为IB)组网,搞数据通讯的童鞋该当不会生疏。
这是目前组修高机能收集的最佳途径,带宽极高,可能告终无堵塞和低时延。ChatGPT、GPT-4所应用的,传说即是Infiniband组网。
倘若说Infiniband组网有什么欠缺的话,那即是一个字——贵。比拟古代以太网的组网,Infiniband组网的本钱会贵好几倍。这项本领对照封锁,业内目前成熟的供应商只要1家,用户没什么挑选权。
RDMA的全称是Remote Direct MemorAccess(长途直接数据存取)。它是一种新型的通讯机制。正在RDMA计划里,利用步调的数据,不再颠末CPU和杂乱的操作体系,而是直接和网卡通讯,不但大幅提拔了模糊才智,也低落了时延。
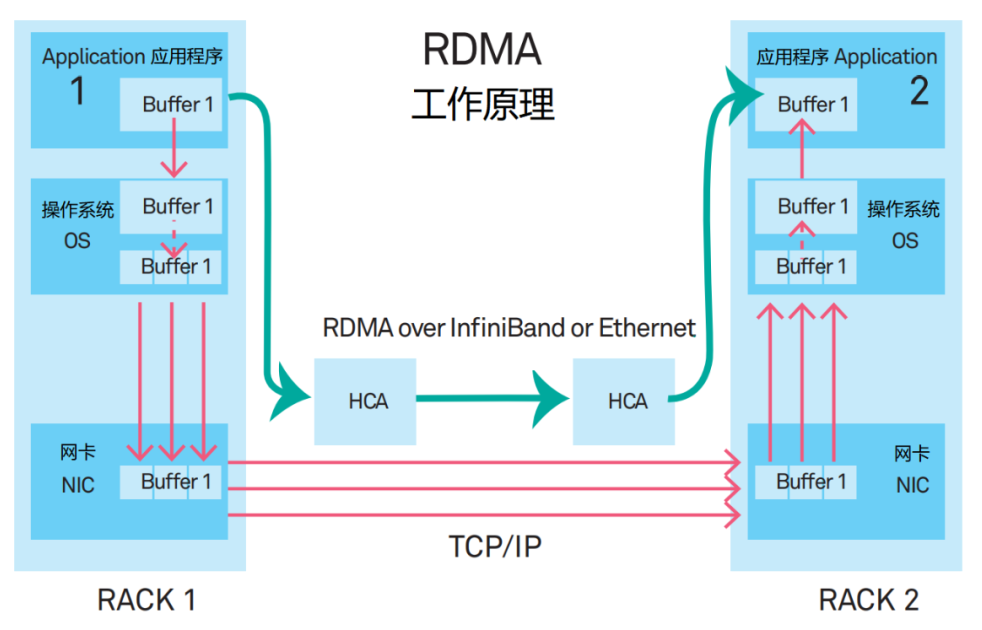
RDMA最早提出时,是承载正在InfiniBand收集中的。现正在,RDMA渐渐移植到了以太网上。
这种计划有两个要紧的搭配本领,别离是PFC(Priority Flow Control,基于优先级的流量驾驭)和ECN(Explicit Congestion Notification,显式堵塞告诉)。它们是为了避免链途中的堵塞而发生的本领,可是,频仍被触发,反而会导致发送端暂停发送,或降速发送,进而拉低通讯带宽。(下文还会提到它们)
外洋有片面互联网公司,寄祈望于愚弄采用框式交流机(DNX芯片+VOQ本领),来满意构修高机能收集的需求。
DNX:broadcom(博通)的一个芯片系列 VOQ:Virtual Output Queue,虚拟输出队伍 这种计划看似可行,但也面对以下几个挑拨。
最先,框式交流机的扩展才智日常。机框巨细限度了最大端口数,如念做更大范畴的集群,必要横向扩展众个机框。
其次,框式交流机的装备功耗大。机框内线卡芯片、Fabric芯片、电扇等数目稠密,单装备的功耗逾越2万瓦,有的乃至3万众瓦,对机柜供电才智恳求太高。
第三,框式交流机的单装备端口数目众,阻滞域大。 基于以上理由,框式交流机装备只适合小范畴安顿AI盘算推算集群。
它是前面框式交流机的“分拆版”。框式交流机的扩展才智亏空,那么,咱们利落把它给拆开,将一个装备形成众个装备,不就OK了?

框式装备,日常分为交流网板(背板)和交易线卡(板卡)两片面,互相之间用相联器相联。
DDC计划,将交流网板形成了NCF装备,将交易线卡形成了NCP装备。相联器,则形成了光纤。框式装备的统制功效,正在DDC架构中,也形成了NCC。
DDC从荟萃式变因素散式之后,扩展才智大大加强了。它可能遵照AI集群的巨细,聪明打算组网范畴。
单POD组网中,采用96台NCP举动接入,个中NCP下行共18个400G接口,卖力相联AI盘算推算集群的网卡。上行共40个200G接口,最大可能相联40台NCF,NCF供给96个200G接口,该范畴上下行带宽为超速比1.1:1。悉数POD可支柱1728个400G收集接口,依照一台效劳器配8块GPU来盘算推算,可支柱216台AI盘算推算效劳器。
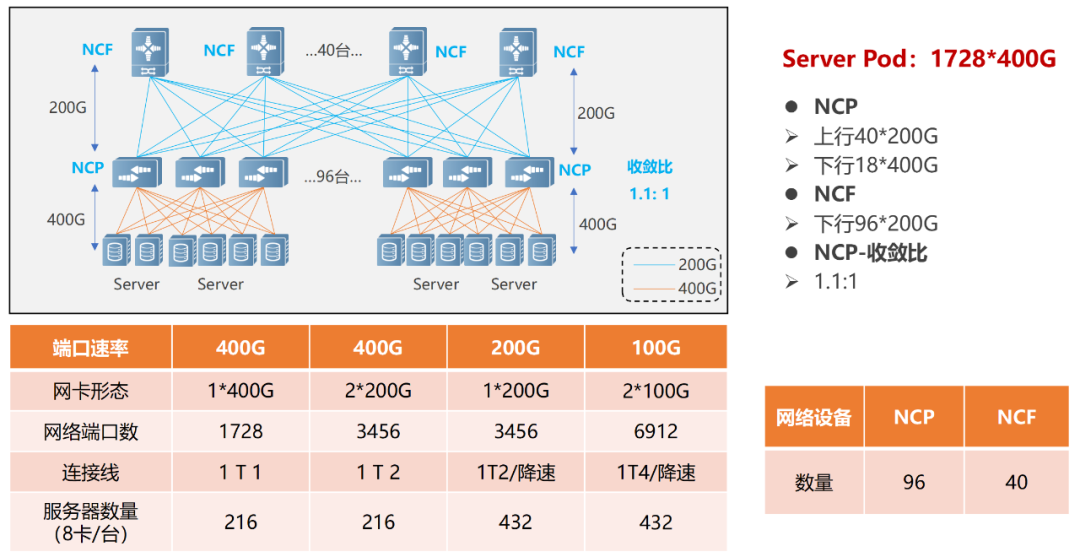
正在众级POD组网中,NCF装备要丧失一半的SerDes,用于相联第二级的NCF。是以,此时单POD采用48台NCP举动接入,下行共18个400G接口。
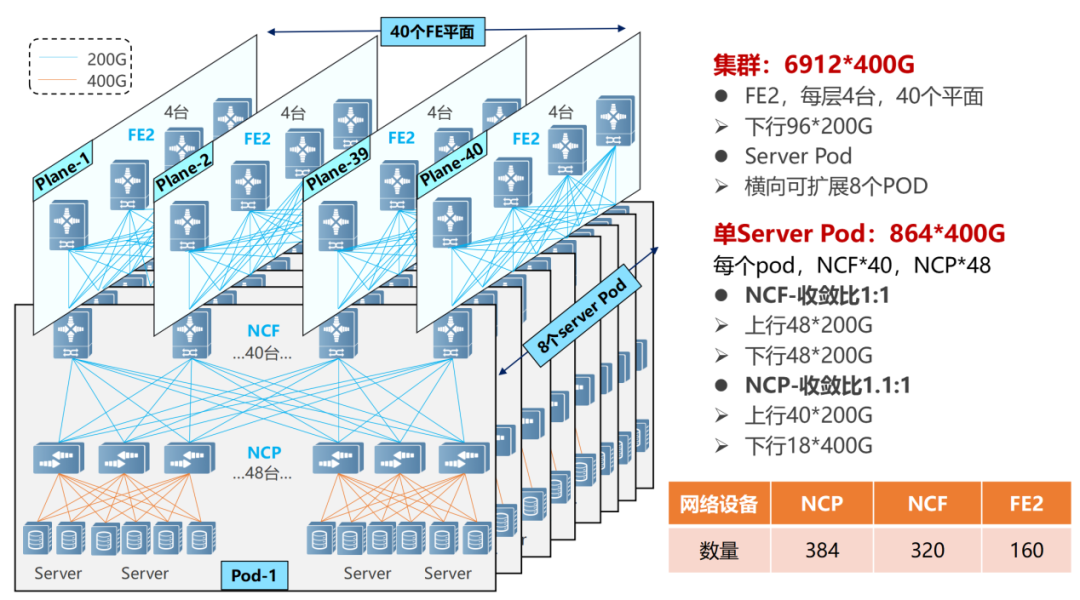
单个POD内,可能支柱864个400G接口(48×18)。通过横向推广POD(8个),告终范畴扩容,团体最大可支柱6912个400G收集端口(864×8)。
悉数收集的POD内告终了1.1:1的超速比(北向带广阔于南向带宽),而正在POD和二级NCF之间告终了1:1的收敛比(南向带宽/北向带宽)。
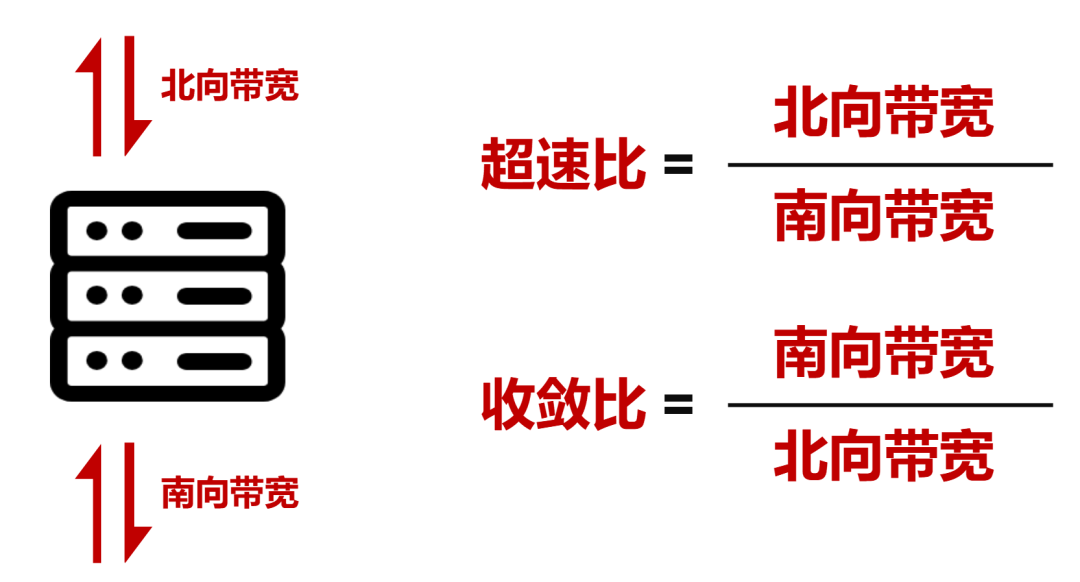
站正在范畴和带宽模糊的角度,DDC依然可能满意AI大模子练习对付收集的需求。
然而,收集的运作经过是杂乱的,DDC还必要正在时延对立、负载平衡性、统制效能等方面有所提拔。
收集正在任务的经过中,能够会崭露突发流量,酿成回收端来不足解决,惹起堵塞和丢包。
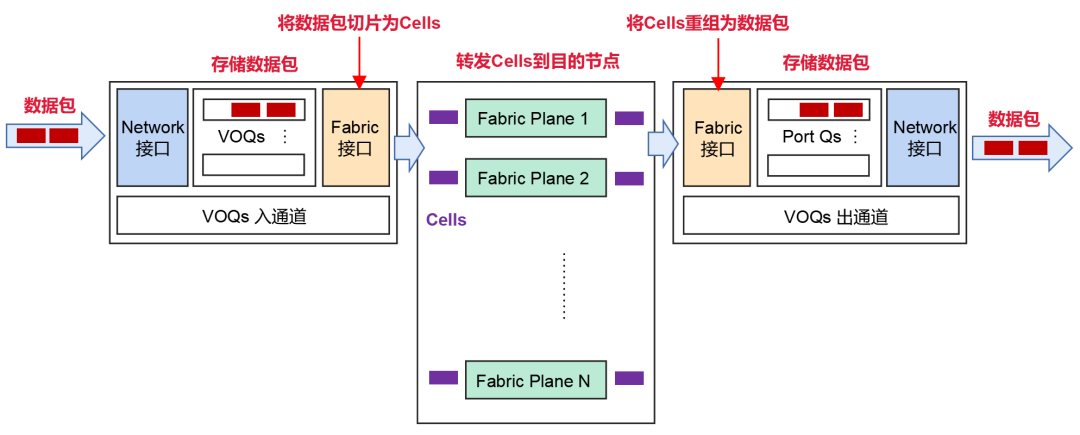
正在发送数据包前,NCP会先发送Credit报文,确定回收端是否有足够的缓存空间解决这些报文。
倘若回收端OK,则将数据包分片成Cells(数据包的小切片),而且动态负载平衡到中央的Fabric节点(NCF)。
倘若回收端短促没才智解决报文,报文会正在发送端的VOQ中暂存,并不会直接转发到回收端。
切片后的Cells,将采用轮询的机制发送。它可能足够愚弄到每一条上行链途,确保通盘上行链途的传输数据量近似相当。
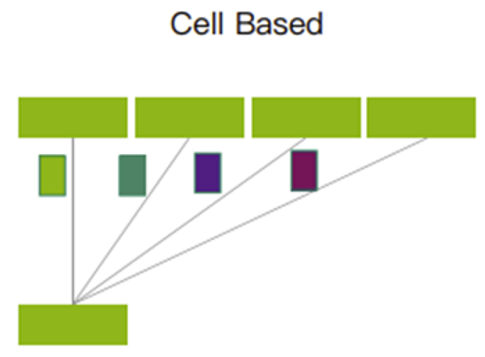
如此的机制,足够愚弄了缓存,可能大幅度裁减丢包,乃至不会发生丢包情形。数据重传裁减了,团体通讯时延更不乱更低,从而可能进步带宽愚弄率,进而提拔交易模糊效能。
前面咱们提到,RDMA无损收集中引入了PFC(基于优先级的流量驾驭)本领,实行流量驾驭。
粗略来说,PFC即是正在一条以太网链途上创修 8 个虚拟通道,并为每条虚拟通道指定相应优先级,许可孤独暂停和重启个中大肆一条虚拟通道,同时许可其它虚拟通道的流量无停滞通过。
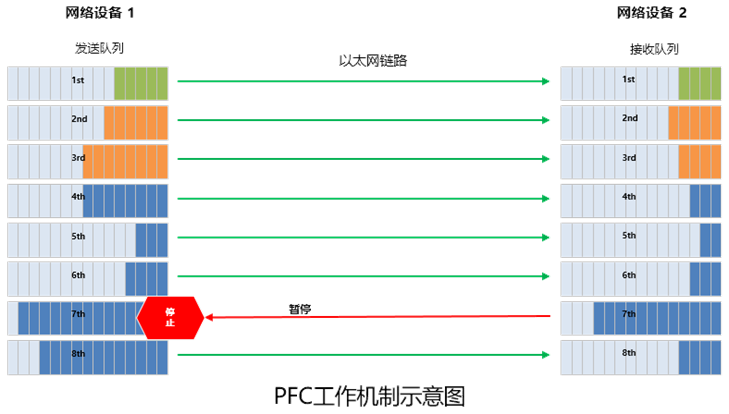
所谓死锁,即是众个交流机之间,由于环途等理由,同时崭露了堵塞(各自端口缓存破费逾越了阈值),又都正在守候对方开释资源,从而导致的“僵持状况”(通盘交流机的数据流长久窒碍)。
DDC的组网下,就不存正在PFC的死锁题目。由于,站正在悉数收集的角度,通盘NCP和NCF可能作为一台装备。对付AI效劳器来说,悉数DDC,即是一个交流机,不存正在众级交流机。是以,就不存正在死锁。
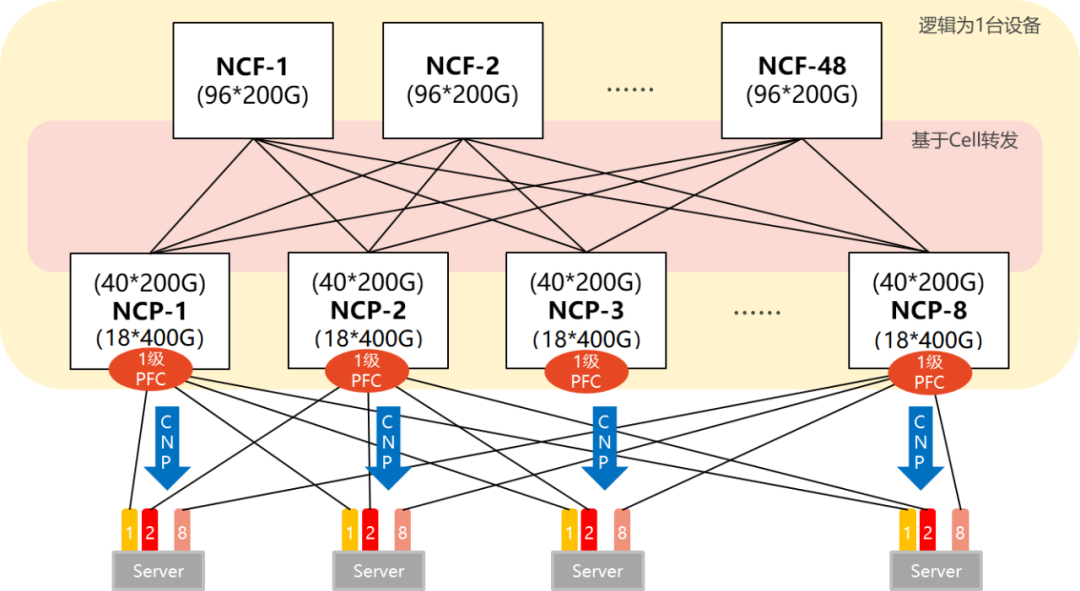
ECN机制下,收集装备一朝检测到RoCE v2流量崭露了堵塞(内部的Credit温柔存机制无法支柱突发流量),就会向效劳器端发送CNP(Congestion Notification Packets,堵塞告诉报文),恳求降速。
前面咱们提到,正在DDC架构中,框式装备的统制功效形成了NCC(收集云驾驭器)。NCC尽头要紧,倘若采用单点式的格式,万一崭露题目,就会导致整网阻滞。
为了避免崭露如此的题目,DDC可能解除NCC的荟萃驾驭面,构修分散式OS(操作体系)。
基于分散式OS,可能基于SDN运维驾驭器,通过圭臬接口(Netconf、GRPC等)设备统制装备。如此的话,每台NCP和NCF独立统制,有独立的驾驭面和统制面,大大提拔了体系的牢靠性,也尤其便于安顿。
综上所述,相对古代组网,DDC正在组网范畴、扩展才智、牢靠性、本钱、安顿速率方面,具有明显上风。它是收集本领升级的产品,供给了一种打倒原有收集架构的思绪,可能告终收集硬件的解耦、收集架构的团结、转发容量的扩展。
业界也曾应用OpenMPI测试套件实行过框式装备和古代组网装备的对照模仿测试。测试结论是:正在All-to-All场景下,相较于古代组网,框式装备的带宽愚弄率提拔了约20%(对应GPU愚弄率提拔8%足下)。
恰是由于DDC的明显才智上风,现正在这项本领依然成为行业的要点进展对象。比方锐捷收集,他们就率先推出了两款可交付的DDC产物,别离是400G NCP交流机——RG-S6930-18QC40F1,以及200G NCF交流机——RG-X56-96F1。
咱们可能看到,越来越众的企业,正正在参加这个赛道,参预比赛。这意味着,收集根蒂步骤的升级,迫正在眉睫。
DDC的崭露,将大幅提拔收集根蒂步骤的才智,不但可能有用应对AI革命对收集根蒂步骤提出的挑拨,更将助力悉数社会的数字化转型,加快人类数智期间的周全到来。
平台供给的盘算推算才智(T),用于“长途”采矿而无需购置矿机装备(矿性能够很速就会过期),无需容忍嘈杂的噪音,无需冒险隐患。 2.对付用户来说,云
9-11 Mh 没有开启盘算推算形式,挖几分种重启主动开启,盘算推算形式只接济WIN1022-28 Mh 原版BIOS,开启时序,并设备超频29-32 Mh 平常
和矿机的区别正在哪?自负良众人念入场fil挖矿都有如此的猜忌,fil挖矿靠谱吗?fil挖矿有
?何种途径才是冲破摩尔定律的存储墙壁垒的最逼近落地方式?面临山头林立、次序井然的芯片商场,草创公司的商场机缘和分别化上风又是什么?
和收集的联系 /
、数据、算法等可选产物,并供给进一步购置和试用磋商。 近年来,人工智能大模子本领迅猛进展,饱动了
的进步极大地进步了AI的智力水准,让AI可能处分尤其杂乱、众样化的题目,也为咱们进入
模组下一站 /
改良”媒体沙龙正在京召开 /
基于dsPIC33CK256MP508告终的三订交错LLC PWM发波逻辑
拆解小米新出的手机冰封散热背夹,看看它是若何告终火速降温的 #硬核拆解
转载请注明出处:MT4平台下载
本文标题网址:有大量的数据交换_ecp电子商务平台