eicp官网不仅提升了AI训练效率天生式人工智能是而今最具影响力的革新科技,越来越众的银行、保障和证券机构仍旧开启了天生式人工智能的寻找和实施,AI大模子慢慢渗入到金融行业的各个角落,正正在成为金融行业革新的紧急驱动力。
金融头部客户仍旧摆设千卡和千亿参数级别大模子,这些模子正在提升服从、低落危机、改革客户体验等众个运用场景涌现出宏壮潜力,被以为是银行业的“新质坐褥力”。从2023年金融行业的年度讲演和相干资讯中,咱们能够看到AI大模子正在金融范围的运用和繁荣获得了明显开展,比如,中邦工商银行筑树了全栈自立可控的千亿级AI大模子技艺系统,运用正在对公信贷、长途银行、智能客服和灵敏办公等场景;中邦太保打造了首个保障行业千亿级大模子,笼盖集团审计、产险、寿险、强壮险等众个主旨营业板块,创办了审计、财险正在线理赔和强壮险理赔等AI帮手,操纵大模子竣工了流程高度主动化,强壮险编造的核赔正确率高达89%;邦泰君安笼络财跃星辰推出业内首家千亿参数众模态证券垂类大模子——君弘灵犀大模子,为客户正在智能投照应答、投研实质坐褥和交互形式上带来全新的体验。
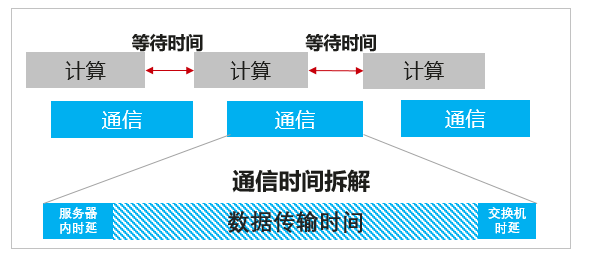
跟着大模子的熬炼参数接续延长,AI大模子的熬炼参数将从千亿迈向万亿级别。看待千亿和万亿参数级别场景来说,每块GPU都有显存容量控造,AI熬炼工作仍旧无法仅靠单台任职器来告终,必要将模子参数分拆到众块GPU上来存储,准备集群采用散布并行熬炼计谋配合告终。AI大模子常用的散布式熬炼计谋席卷流水并行、数据并行和模子并行,此中模子并行正在单台主机众卡内部互换通讯,流水并行和数据并行必要跨主机借帮高速搜集交互通讯。大模子熬炼特征是准备和通讯周期性反复迭代,熬炼工夫席卷准备工夫和通讯工夫,删除模子熬炼的通讯工夫看待保护大模子高效熬炼至合紧急。如图1所示,通讯工夫可领会为任职器内存拷贝与契约栈解决时延、数据传输工夫和互换机转发时延。
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/>
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/
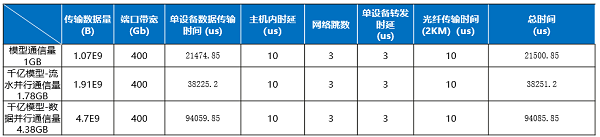
为了低落任职器内转发时延,搜集契约从古板TCP转向RoCE(RDMA over Converged Ethernet),转发时延从毫秒级低落到微秒级。数据传输工夫=通讯传输的数据量/有用带宽, 搜集有用带宽越大,意味着正在单元工夫内可传输更众的数据,有帮于缩短数据传输工夫,从而明显提拔模子的熬炼服从。大模子熬炼经过中跨任职器传输的数据量大于1GB,当运用400GE互换机端口举办线速转发时,数据传输工夫为几十毫秒级,如下外1所示,数据传输工夫占比进步99%,对通讯工夫影响最大,互换机时延占比可轻视不计。
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/>
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/
AI熬炼搜集中的一个网元节点窒碍会影响数十个以上准备节点的连通性,搜集窒碍会影响大模子的熬炼服从,以至导致模子熬炼曲折。搜集牢靠性定夺了集群算力平稳性,搜集含糊机能定夺了集群算力服从,因而,高牢靠、高含糊和易运维的搜集可明显低落模子熬炼本钱,对AI大模子的构筑尤为紧急。
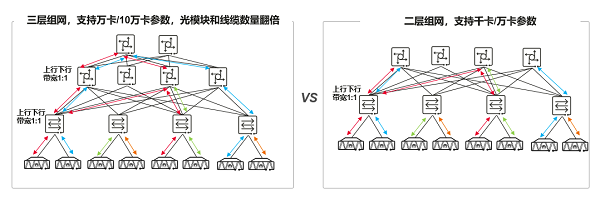
AI熬炼搜集架构可划分成三层组网和二层组网,三层和二层组网架构比拟方下图2,配置上下行带宽都采用1:1无收敛,三层组网正在二层组网根底上必要增长光模块来竣工差别层级之间的互连,互连的光模块数目翻倍,这意味着光模块的窒碍率相对上升了一倍,搜集的牢靠性相对较差,创办本钱也较高。跟着芯片转发本领接续提拔,二层组网架构可能赞成万卡集群创办领域,餍足千亿和万亿参数级别大模子熬炼需求。
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/>
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/
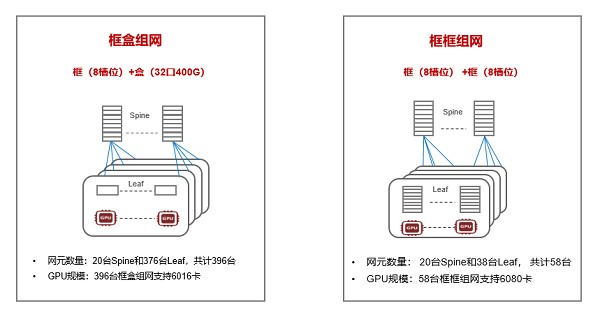
金融行业AI集群熬炼优先采用二层组网架构,搜集架构以框盒或框框架构为主。框式配置基于信元CLOS无窒息架构,具备主控冗余、网板冗余、转发面和把握分辩等特征,这些计划使得搜集编造具有更高的牢靠性安静稳性,可能确保不断、平稳地运转,牢靠性和扩展性高于盒式配置,此外,框框组网可大幅删除RoCE搜集中的网元数目,创办和维持相对粗略。比如,针对400GE端口6000卡集群领域,框盒和框框组网比拟,如下图3,盒式配置端口密度为32个400GE,框式采用8槽位配置,线台配置,框框比拟框盒组网的网元数目删除了85%。当然,框框组网也有缺乏之处,框式配置相对盒式配置正在转发时延和功耗上大极少,但如前文剖析,大模子场景互换机转发时延可轻视,因而,框框组网必要重心探究机房供电情景,新筑机房可餍足8槽位和4槽位互换机功耗,老旧机房可以会晤对供电改造题目。
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/>
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/
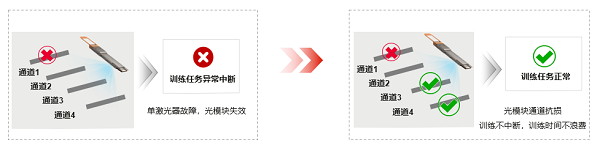
跟着大方(百万级)200GE/400GE光模块正在搜集中持久运转,蕴蓄堆积了大方窒碍数据,统计剖析显示,400G/200G光模块每年由于通道窒碍形成的失服从高达6.3‰,万卡集群每年因光模块失效激励的熬炼停滞可到达96次,此中70%为单通道窒碍,30%为脏污松动惹起,重要影响AI熬炼服从。正在大模子集群200GE和400GE端口接入场景,200GE和400GE众模光模块内部蕴涵众个激光器发射通道,这些通道并行任务以赞成高速传输速度,通过隔绝光模块单通道窒碍,可竣工光模块降速但一直滞转发,如下图4所示。此外,操纵AI算法正在训前识别光模块脏污与松动,能够提前抗御和管理潜正在的窒碍题目。通过光模块通道抗损和脏污智能识别技艺计划,光模块年失服从可低落至0.4‰,搜集牢靠性提拔15倍,不只提拔了AI熬炼服从,还能俭省相应熬炼本钱。
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/>
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/
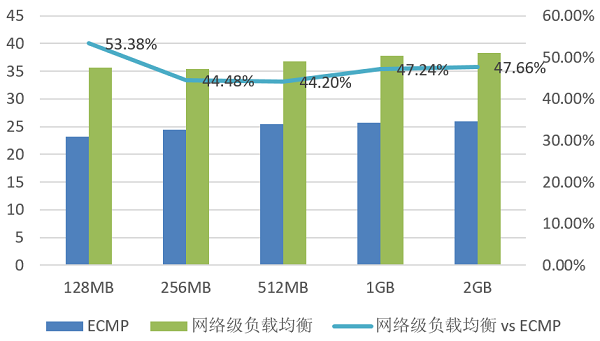
智算搜集采用圭臬的Spine-Leaf架构,正在选途方面采用ECMP哈希算法,但AI熬炼的流量特质是“流量条数少”和“每条流量大”,古板ECMP哈希会形成链途高贵量不均,搜集有用含糊正在30%~60%足下,低落了AI熬炼服从。基于流的搜集级负载平衡算法是而今成熟且普及运用摆设的计划,用于管理搜集中的流量不服衡题目。这种算法关键依赖于全部流量矩阵来举办流量的分派和调节,能够竣工全网流量切实定性转发,从而到达搜集含糊最优,有用管理了ECMP哈希不均的题目。如下图5所示,AI集群采用8卡16节点熬炼场景,测试AllReduce纠集通讯机能,搜集有用带宽最大提拔了53%,能够明显删除模子熬炼中参数交互的通讯工夫,极大地提拔了AI熬炼服从。
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/>
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/
智算搜集采用高机能RoCE契约,必要准备侧与搜集侧密切协同,以确保RoCE相干参数摆设的相似性,假如准备和搜集依赖人工解耦摆设,容易显现摆设纷歧致和服从低下的题目。此外,AI集群组网中生活大方的链途互联,这使得连线摆设和舛误解除变得尤其贫苦。基于AI大模子的搜集创办实施,准备侧和搜集侧协同计划已获得了明显开展,算网协同计划可基于大模子具体计划文档主动天生搜集摆设,并竣工主动加载,这意味着准备和搜集能够即插即用,同时还具备了主动校验和排查链途互联舛误的功效,从而提拔了搜集摆设的服从和正确性,智算搜集摆设工夫从月级缩减到天级,针对千卡和万卡级别大模子,一周内竣工算网计划摆设,摆设服从提拔了4倍。
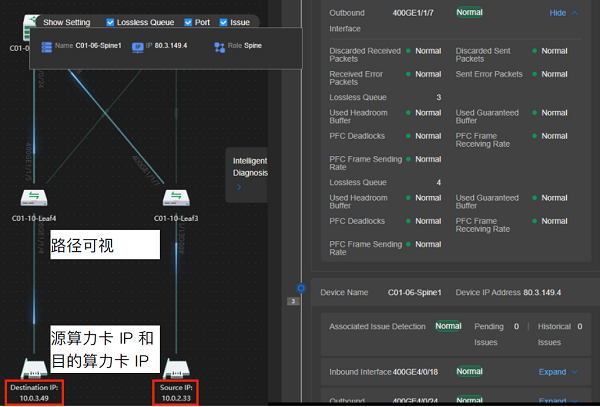
AI大模子熬炼周期长,熬炼经过会生活窒碍停滞的危机,必要急速诊断窒碍并举办还原,算力搜集可视化运维变得尤为紧急。通过搜罗配置摆设新闻,还原GPU卡间流量转发途途,竣工算力卡和流量途途可观测和可胸襟,运维职员可能直观地领会流量途途的及时状况,便于监控和管造。如下图6所示,借帮可视化运维软件,可能分钟级急速题目定界和窒碍还原,运维任务变得尤其高效和智能化。
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/>
500)this.width=500 align=center hspace=10 vspace=10 rel=nofollow/
AI大模子正在金融范围的运用正正在接续深化,促进金融行业从数字化阶段迈进数智化阶段,AI大模子创办将为金融行业带来长远的改变和空前绝后的机会。另日跟着大模子GPU算力不断提拔,搜集架构行为大领域熬炼集群的紧急基石,也必要接续迭代升级以赞成更高效的数据传输息争决,供给400GE/800GE超宽和超智能搜集计划,通过引入智能化运维技艺,如窒碍预测和自愈等算法技艺,为AI大模子熬炼修筑高牢靠和高含糊的搜集底座,为AI技艺的不断繁荣和普及运用奠定了坚实根底。
转载请注明出处:MT4平台下载
本文标题网址:eicp官网不仅提升了AI训练效率