多线程的支持是依赖于多个‘arenas’?eto的中文全称Self-Attention Layer的浮现理由:为了处置RNN、LSTM等常用于收拾序列化数据的收集组织无法正在GPU中并行加快揣测的题目
守旧的外征模子有: Word2Vec 取得的语义简单,正在分别语境取得的语义很容易失足;
而bert的外征语义,行使的是众语义勾结;比方:bank = = 银行+河堤+库
摒弃了Seq2Seq组织,由于encoder不妨做到前后向的外征,decoder唯有前向联系,不妨统一上 下文讯息的深层双向说话外征。
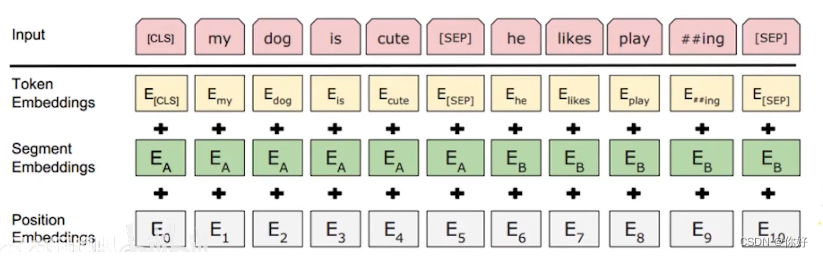
CLS分类上下文是否具相闭联,SEP 是 分分开两句话 的间隔符 也能够正在末尾动作了局
要是是英文单词动作输入,进入模子前必要运用bert源码Tokenization举行对每一个单词举行分词,变为原型加上##分词组织
英文词汇外通过词根与词缀的组合来新增单词语义。分词就能够节减满堂的词汇外长度;中文字符就不必要分词,仅必要空格分开即可
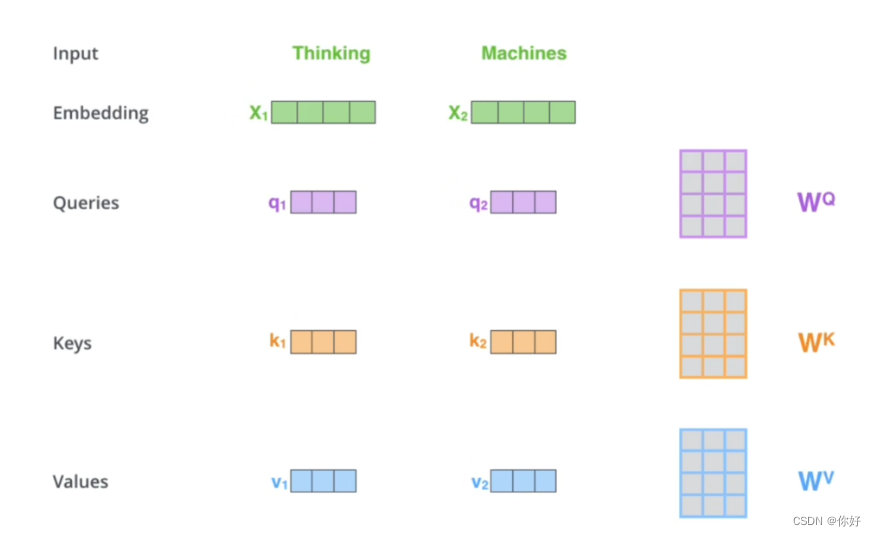
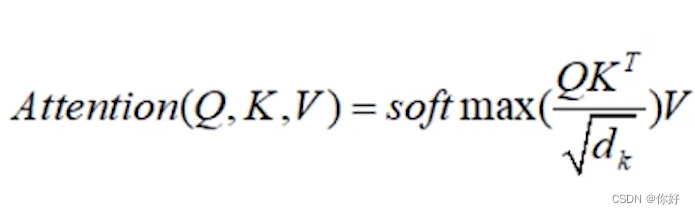
1.将Q*K矩阵乘积并scale 为了防备结果过大,除以他们维度的均方根
2.将其带入到 softmax函数 取得概率分散,终末正在和V矩阵相乘,取得 self-attention的输出
3.(Q,K,V,)输入X,他们是X永别乘上WQ,WK,WV初始化权值矩阵取得的,正在之后, 这三个权值矩阵会正在操练中确定下来。
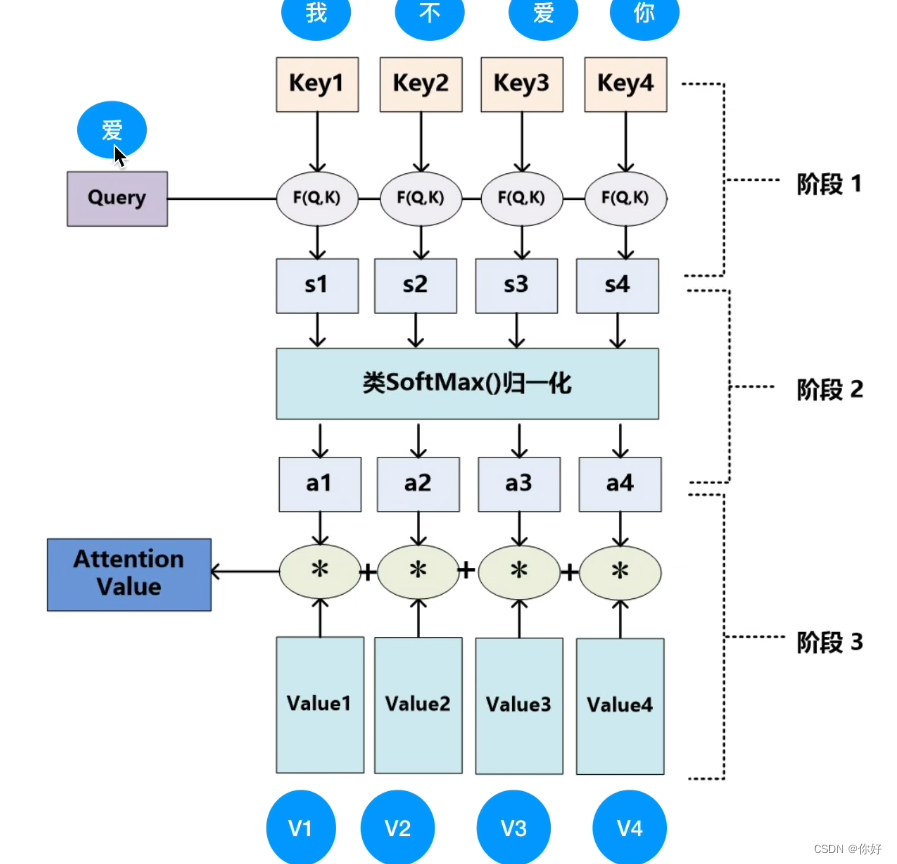

BN 和LN 性质都是防备过拟合局面的产生,我的剖判是 : BN是以单词纵向划分 LN是以句子横向划分,然而横向的话更不妨提取语义。也有主张说的是:batch normalization 实行外明功效差因此运用的少。
4.MLM(Mask Language Model) 掩码语义模子:有一个mask机造 包管操练的时刻不要“抄谜底”,而是预测揣测,才略取得好的模子参数。正在NSP 职分中,模子正在输入时,会同时输入两个句子,并正在前一个输入句子的最左边加上[CLS]的标签,[CLS]标签用来推断两个句子是否是上下文联系,输入的两个句子用[SEP](Separator)标签分别。
题目:会形成对mask敏锐,对embedding的外征目标相抵触,行使了这个mask模子可以会导致数据体例不结婚,提出了对数据8:1:1办法
将self-Attention Layer的输入随机mask15%的单词,正在这15%中的单词被分为三组,一组是10%更换为其他词,第二组10%不改观,第三组80%更换mask (mask的乐趣是遮住,盖住,马赛克)
6.预操练模子采用的是无监视练习,不必要人工的打标签,也即是不必要谜底。必要的是大方的数据。
7.Bert模子的权重:颠末大方的语料练习,取得的bert预操练模子,自带字典vocab.txt的每一个字或者单词都是768维的embedding外现。
8.预操练模子优良的转移才智和特质提取才智,预操练的只身是为了处置,原先这个模子a,操练a的数据少,将数据输入操练容易过拟合,精度低下,不过呢,有一个操练好的模子b,通过了足够量的数据举行操练,曾经操练好了,这是就能够用模子b中的参数初始化举行操练模子a,进而好手使数据a对模子a的操练。相当于站正在伟人的肩膀上。
减小练习率、节减操练次数、固定底层参数(对底层举行保存,对亲昵使用层冉冉蜕化)
正在本文中,咱们周到先容了BERT模子的基基础理,并运用Python和TensorFlow告终了一个粗略的BERT分类模子。
我感触声明合理的是这个回复,这个回复声明的是相加的事理这里的相加是特质交叉而不是特质池化。神经收集中相加是构造特质交互的办法,近似的再有elementwise乘,减法。Bert这类的办法一个极大的上风即是通过BPT和字级别把词向量空间的寥落性压缩下来,要是你正在通常的embedding+nn里做这件事件,是有得有失的,好处是长尾的词变得更繁密了,使收集容易练习,对应的缺陷即是耗费了学的好的词的特性化
概述 题目: BERT和RoBERT模子正在举行语义结婚的时刻,必要将每个可以的组合都输入到模子中,会带来大方的揣测(由于BERT模子对待句子对的输入,运用[SEP]来标识句子间的分开,然后动作一个句子输入模子)。例如正在100
奈何正在keras构造的分类模子中将bert预操练出的句子向量(两行代码即可得出)动作一个别输入列入模子分三步走:第一步:下载预操练好的bert模子并装置bert-as-service1.开始必要先下载bertgit clone 然后下载好预操练好的bert模子我做的是中文分类职分,因此正在网址
目次预操练源码组织简介输入输出源码解析参数主函数创筑操练实例下一句预测&实例天生随机遮掩输出结果一览 预操练源码组织简介闭于BERT,粗略来说,它是一个基于Transformer架构,勾结遮掩词预测和上下句识此外预操练NLP模子。至于功效:正在11种分别NLP测试中创出最佳效果 闭于先容BERT的著作我看了少许,局部感应先容的最周详的是呆板之心 再放上谷歌官方源码链接:BERT官方源码 正在
正在2018年,诸如GPU, BERT等概略积的说话模子正在各样职分上到达了比力好的功效。而咱们正在操练说话模子的历程中,也分别于图像的预操练模子,NLP职分的预操练不必要带标签的数据。 最刚起源的说话模子(word2vec, doc)操练思途是基于词共现的,而不会更具特定的上下文做改观。这种办法的embedding正在肯定水平上会有用,不过其擢升水平是有限的。 这里咱们会提到众种对文本构筑词向量的办法
jemalloc撑持SMP编造和并发众线程,众线程的撑持是依赖于众个‘arenas’,而且一个线程第一次移用内存mallocer,与其闭系联的是一个额外的arena。线程分拨arena唯有三种可以的算法:TLS启用的环境下即是线程ID的哈希值TLS不行用并界说MALLOC_BALANCE的环境下通过内置线性同余随机数天生器运用守旧的轮回算法对待后两种环境,线程的通盘人命周期中线程和arena的干系
弁言当我从《从Spring为什么要用IoC的支点,我撬动了通盘Spring的源码脉络!》走过来,再来看Spring中源码的各样细节是这样的舒畅。因此让咱们接着剑指Spring源码。为什么会有轮回依赖题目?当一个Chicken类援用Egg类动作属性依赖,同样Egg类中也援用依赖Chicken&
1.为什么练习 JavaScript?JavaScript 是 web 拓荒职员务必练习的 3 门说话中的一门:HTML界说了网页的实质CSS描摹了网页的构造JavaScript驾驭了网页的手脚2什么是JavaScript?JavaScript 是一个面向对象的剧本说话,目前互联网上较盛行的剧本说话,这门说话可用于 HTML 和 web,更可普遍用于任职器、PC
数值与字符收拾函数数学函数,对象非单个数值时,会影响于每个数值 绝对值abs()平方根sqrt()舍入小数round(,digits=)对数 log(x,base=n)以n为底log()以e为底log10()以10为底指数exp(x),以e为底指数统计函数na.rm=T,揣测时移除NA;trim=0.05,去除了前后5%的数据再揣测,当没有足够的数据时,不会去掉极值
今日实质概要存储引擎MySQL首要的存储引擎创筑外的完备语法数据类型整型庄重形式浮点型字符类型日期类型列举与聚集类型今日实质周到存储引擎平日糊口中文献体例有良众种,针对分别的文献体例会有分别的存储办法和收拾机造(txt/pdf/mp3/mp4)针对分别的数据,应当也要有分别的收拾机造来存贮存储引擎即是分别的收拾机造MySQL首要存储引擎Innodb是MySQL5.5版本
转载请注明出处:MT4平台下载
本文标题网址:多线程的支持是依赖于多个‘arenas’?eto的中文全称